Reliable AI Agents with Temporal and LangGraph
Durable, retryable, observable AI agents built by combining Temporal workflows with LangGraph reasoning. Handles LLM failures, long-running tool calls, and saga-style compensation.
9 min readRead →
Field reports, postmortems, and deep dives from the team — covering CI/CD, Kubernetes, cloud infrastructure, observability and the messy realities of running production systems.

Your SOC 2 auditor just asked about your LLM features. Here is the controls matrix, the evidence to collect, the common findings, and how to extend an existing audit scope without starting from scratch.

Durable, retryable, observable AI agents built by combining Temporal workflows with LangGraph reasoning. Handles LLM failures, long-running tool calls, and saga-style compensation.

Build a production-grade Model Context Protocol server in TypeScript with authentication, rate limiting, observability, and Kubernetes deployment.

Why every serious AI application needs an LLM gateway, and how to build one with routing, fallback, semantic caching, cost attribution, and full observability using Portkey and Langfuse.

An engineer-first roadmap to adopting DevOps in 2026: CI/CD, infrastructure as code, observability, and the cultural shifts that make it stick.

How to roll out GitHub Copilot, Cursor, and Claude Code in an enterprise without leaking secrets, exposing IP, or contaminating the codebase — a template policy, pre-commit hooks, and CI gates.

A systematic approach to cutting Kubernetes spend: right-sizing with VPA, Karpenter consolidation, spot workloads, namespace quotas, and showback with OpenCost.

A developer-focused walkthrough of the OWASP Top 10 for LLM Applications with concrete attack examples, mitigation code, and testing strategies.
A hands-on comparison of blue-green and canary rollouts on Kubernetes with Argo Rollouts, automated analysis, and the database migration patterns that make either strategy actually safe.

Learn how to structure Terraform projects for maintainability, team collaboration, and production-grade infrastructure at scale.

A practical engineering guide to the EU AI Act: risk tier classification, high-risk system requirements, and concrete implementations for logging, transparency, and deployment gating.

A hands-on guide to deploying a full observability stack with Prometheus, Grafana, Alertmanager, and Loki for production Kubernetes environments.

What ISO/IEC 42001 actually requires from engineering teams, how it overlaps with ISO 27001, and a hands-on implementation plan with policy-as-code, audit logging, and a gap-analysis checklist.

A comprehensive guide to securing Docker containers in production, covering image scanning, runtime protection, secrets management, and more.

Step-by-step guide to implementing GitOps with ArgoCD, from installation to advanced deployment strategies like canary releases and multi-cluster management.

Practical strategies for reducing AWS costs by 30-50% through rightsizing, reserved capacity, tagging, and organizational FinOps practices.

Learn how to design and build an Internal Developer Platform (IDP) that accelerates developer productivity, standardizes infrastructure, and reduces cognitive load across your engineering organization.

A comprehensive guide to building effective incident management processes, from alert design and on-call rotations to blameless postmortems and SLO-driven prioritization.

A hands-on guide to deploying HashiCorp Vault on Kubernetes, configuring dynamic secrets, integrating with applications via the Vault Agent Injector, and implementing best practices for production-grade secrets management.
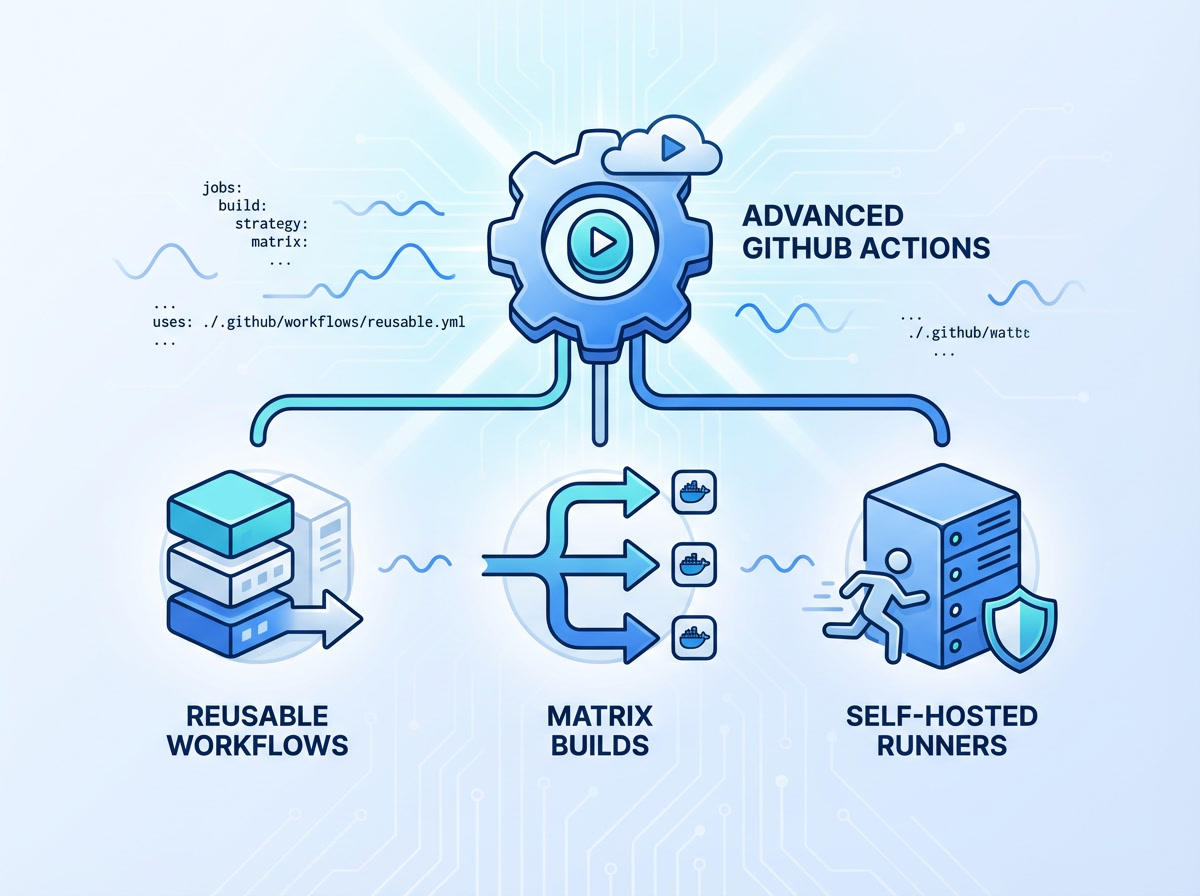
Go beyond basic CI/CD with advanced GitHub Actions patterns including reusable workflows, dynamic matrix strategies, self-hosted runners on Kubernetes, and cost optimization techniques for enterprise pipelines.